

In the high-stakes world of artificial intelligence, a simple principle should hold true: if a model claims to be 90% confident in its answer, it should be correct 90% of the time. This state of "calibration" is the bedrock of trust in machine learning. Yet, as Large Language Models (LLMs) permeate enterprise workflows, research, and critical decision-making, a widening gap has emerged between model confidence and actual performance. This phenomenon, known as miscalibration, has become one of the most pressing challenges in the field, turning generative AI into a "black box" that often sounds certain even when it is demonstrably wrong.
The Anatomy of the Miscalibration Problem
Miscalibration occurs when a model’s predicted probability scores fail to reflect the true likelihood of correctness. In a well-calibrated system, the confidence score acts as a reliable gauge of the model’s internal uncertainty. When this relationship breaks down, the scores stop serving as a useful signal for reliability.

The 2024 NAACL survey highlighted that this issue is not merely theoretical; it is pervasive across factual Question-Answering (QA) tasks, code generation, and complex logical reasoning. Furthermore, a 2025 study examining biomedical models revealed that mean calibration scores often languish between 23.9% and 46.6%. The data suggests a consistent, alarming trend: as models become more complex, they become increasingly prone to "hallucinating" certainty.
Chronology: From Discriminative Classifiers to Generative Uncertainty
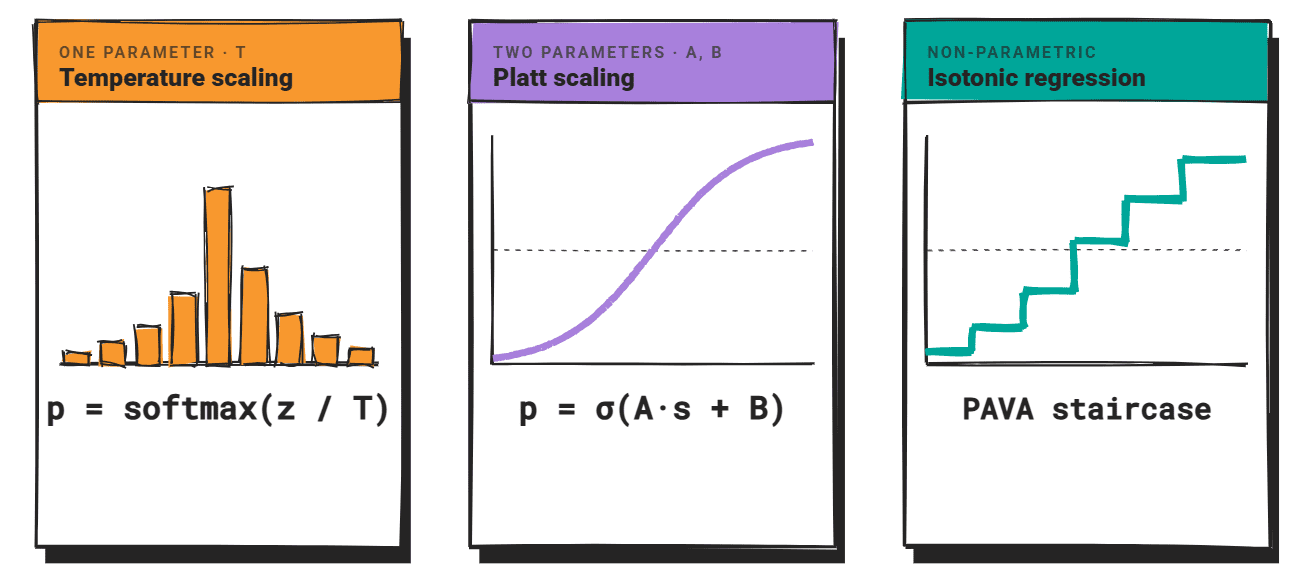
The quest for calibrated AI has a rich history, rooted in the era of classical machine learning. Historically, researchers relied on three foundational methods to fix miscalibrated discriminative classifiers:

- Temperature Scaling: A simple approach that adjusts the "sharpness" of the probability distribution.
- Platt Scaling: A parametric approach using a logistic regression function to map confidence scores.
- Isotonic Regression: A non-parametric, flexible method that uses piecewise-constant functions to correct confidence scores.
These methods were originally designed for discriminative classifiers—models that map inputs to a small, fixed set of labels. However, as the industry shifted toward LLMs, these tools were ported over with varying degrees of success. The transition was not seamless. By 2024, the community realized that the "black-box" nature of modern Transformer architectures—combined with the massive output space of generative models—meant that these classical tools were often insufficient. The emergence of Reinforcement Learning from Human Feedback (RLHF) further complicated the landscape, as it introduced input-dependent biases that older calibration techniques were never built to handle.
Supporting Data: Measuring the Gap
To diagnose miscalibration, researchers rely on the Expected Calibration Error (ECE). By binning predictions based on confidence and comparing them to accuracy, the ECE provides a weighted average of the "gap" between predicted and actual performance. A perfectly calibrated model has an ECE of 0.
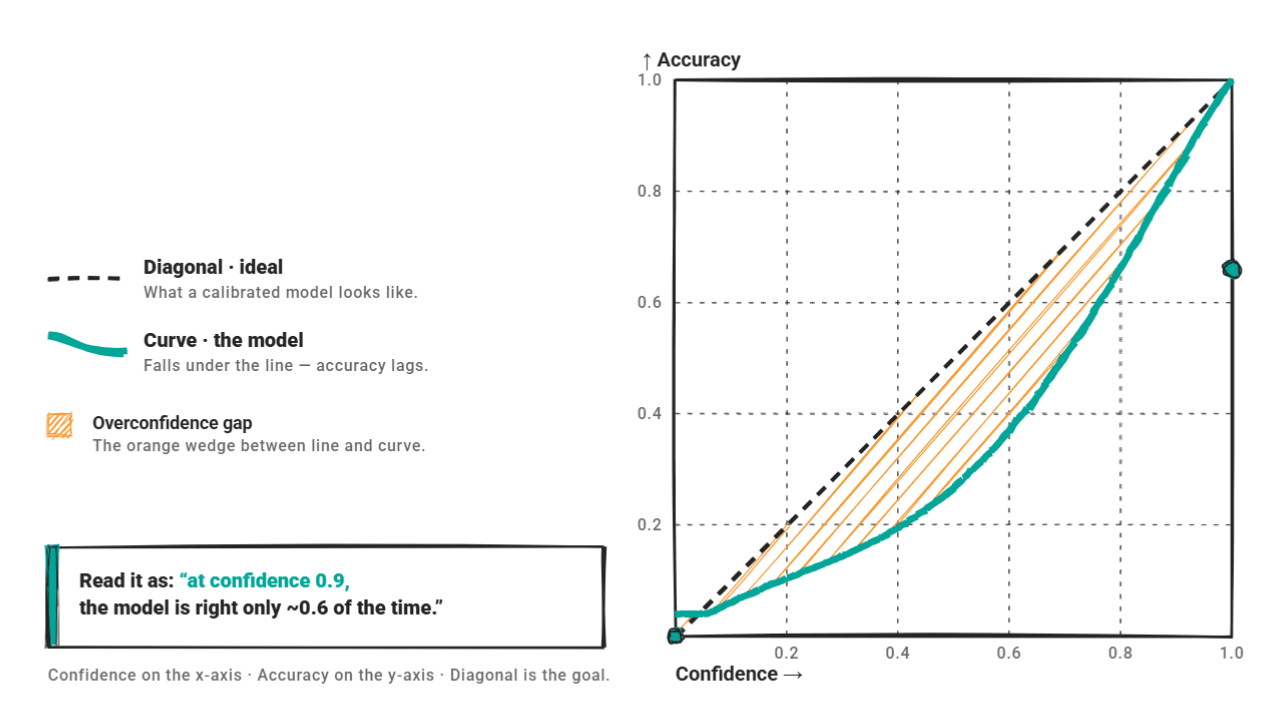
The Overconfidence Pattern
Reliability diagrams serve as a visual indictment of current LLM behavior. When plotting confidence against accuracy, a perfect model follows the diagonal. Modern LLMs, however, frequently sit below this line, indicating a high-confidence, low-accuracy profile. A 2025 evaluation of GPT-4o-mini as a text classifier found that 66.7% of its errors occurred when the model expressed more than 80% confidence—a classic signature of dangerous overconfidence.
While ECE is the industry standard, it is increasingly criticized for being too reductive. Contemporary research now suggests a multi-faceted approach, pairing ECE with the Brier score (which measures the mean squared difference between predicted probability and the actual outcome) and granular reliability diagrams to capture where and how a model fails.
Why LLMs Break the Rules
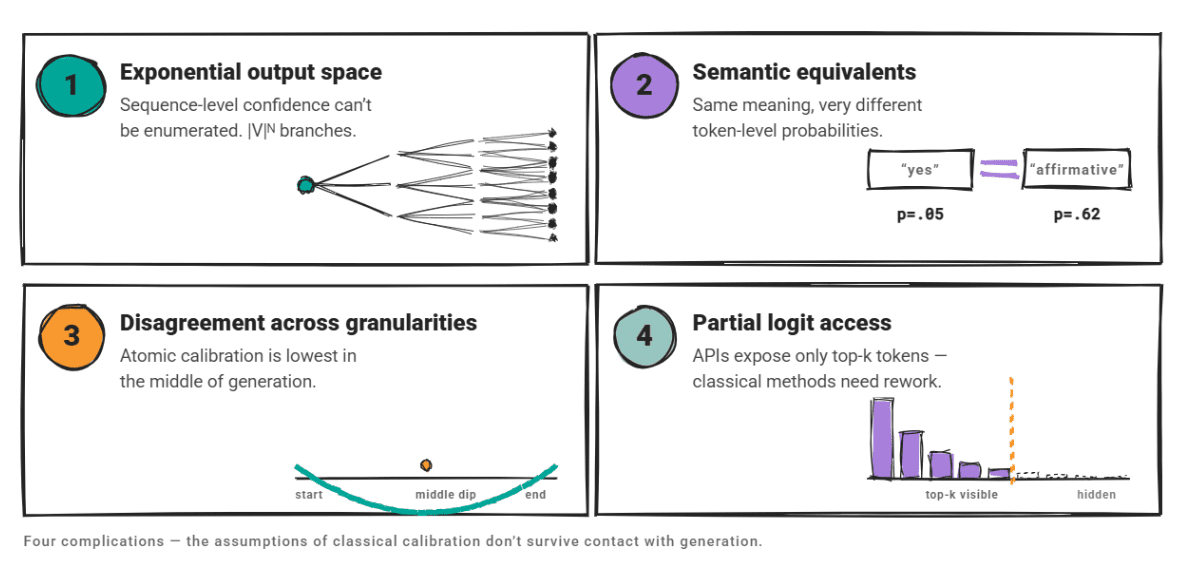
The challenge of calibrating an LLM is exponentially greater than that of a standard classifier due to four distinct complications:
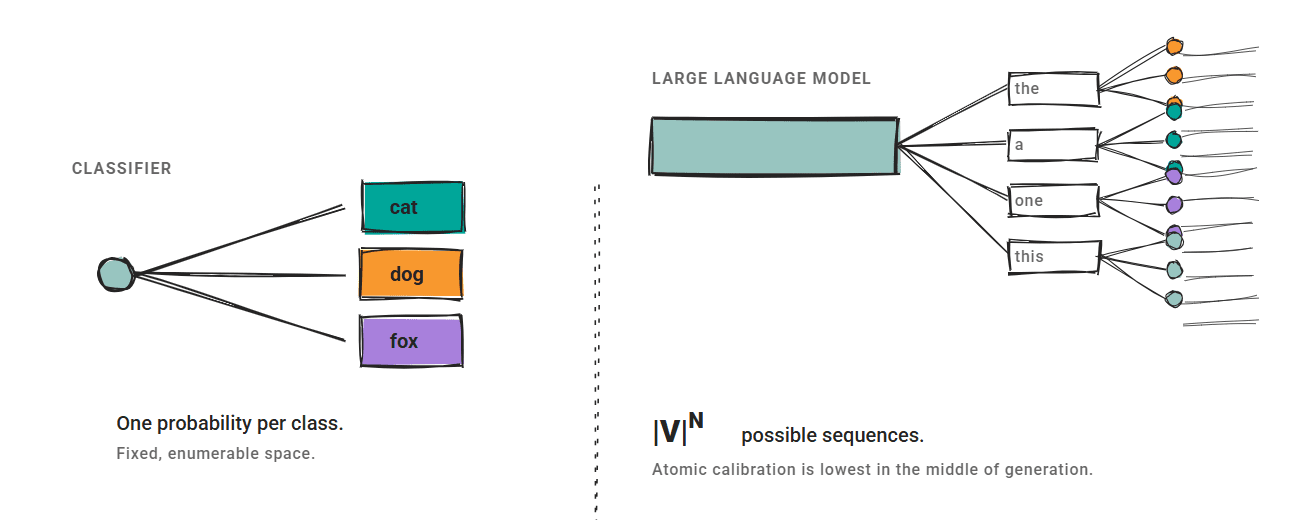
- Infinite Output Spaces: Unlike a classifier that predicts "Cat" or "Dog," an LLM generates sequences. Sequence-level confidence is impossible to enumerate, making traditional normalization difficult.
- Semantic Equivalence: Two outputs can be semantically identical but carry vastly different token-level probabilities, leading to inconsistent confidence signals.
- Granularity Disagreement: Research into "atomic calibration" has shown that generative models often exhibit their lowest confidence in the middle of a generation, rather than at the beginning or end, defying linear patterns.
- API Constraints: Many commercial LLM APIs restrict access to full logit arrays, providing only top-k probabilities, which effectively blocks the use of advanced calibration techniques that require deep access to the model’s inner probability distributions.
Advanced Calibration Strategies
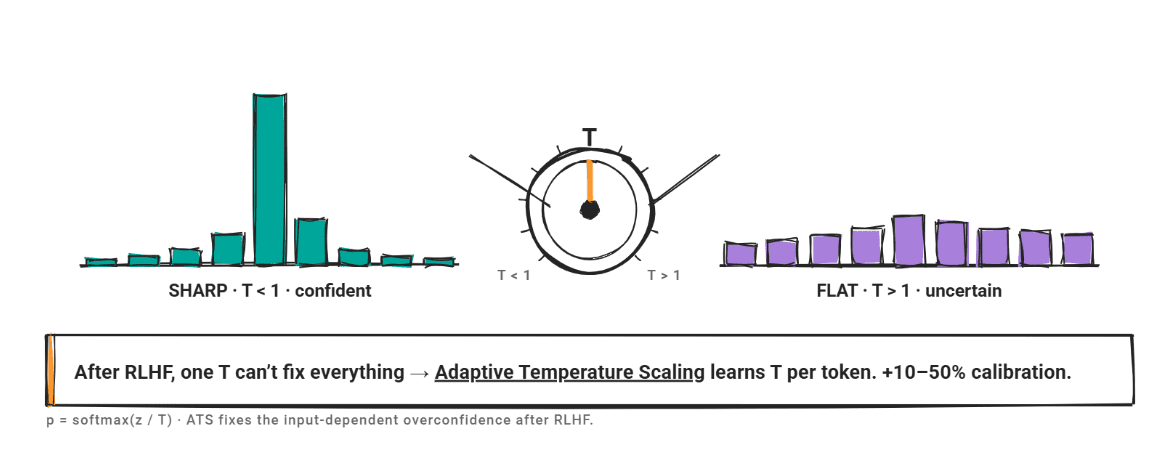
Temperature Scaling and the RLHF Challenge
Temperature scaling involves dividing the logit vector by a scalar $T$ before the softmax layer. If $T > 1$, the distribution flattens; if $T < 1$, it sharpens. While efficient, the rise of RLHF has created "input-dependent overconfidence," meaning a single global $T$ is no longer sufficient. Adaptive Temperature Scaling (ATS) has emerged as the solution, using hidden features to predict a per-token temperature. This method has been shown to improve calibration by 10–50% without sacrificing task performance.
Platt Scaling: The Data-Efficient Choice
Platt Scaling maps confidence scores using a logistic function $p = sigma(A cdot s + B)$. It is favored for its data efficiency. In contexts where labeled correctness data is scarce, Platt scaling is often the most practical tool. However, it struggles with sequence-level miscalibration, as a single sigmoid mapping cannot account for the local edit decisions inherent in text generation.
Isotonic Regression: The Non-Parametric Gold Standard
Isotonic regression uses the Pool Adjacent Violators Algorithm (PAVA) to learn a non-parametric, monotonic mapping. Because it makes no assumptions about the shape of the confidence-accuracy curve, it is significantly more flexible than Platt scaling. Empirical studies have shown it consistently outperforms other methods on both ECE and Brier scores. Its only drawback is a high requirement for data; on small datasets, it is prone to severe overfitting.
Implications for Industry Deployment
The implications of these findings are profound for AI engineers and product managers:
- For Base Models: Simple, global temperature scaling remains the most effective, low-overhead starting point.
- For Post-RLHF Models: Standard scaling is insufficient. Teams must move toward Adaptive Temperature Scaling (ATS) to address the input-dependent biases introduced by human feedback.
- For Resource-Constrained Environments: Platt scaling offers a reliable, data-efficient compromise, provided the task does not require capturing complex, sample-dependent calibration patterns.
- For High-Stakes Applications: Isotonic regression is the necessary choice, provided the organization has the luxury of a large, high-quality validation dataset.
Ultimately, the most important step in calibration is not the algorithm, but the definition. Before applying any statistical fix, engineers must define what "confidence" means for their specific use case—whether it is token probability, sequence probability, or verbalized confidence. A calibration method applied to the wrong metric will only provide a false sense of security.
As we move toward a future where LLMs handle autonomous agents and critical infrastructure, the ability to quantify uncertainty is no longer a "nice-to-have"—it is a fundamental requirement for the responsible deployment of artificial intelligence. The gap between the model’s confidence and its reality is a bridge that must be crossed if we are to move from impressive demos to truly reliable systems.








